Run Kiln, open the UI, and send one chat request.
Start with the Desktop App if you want the shortest path. Use a server binary or Docker when you want a terminal-first setup. Every path serves the same single target model: Qwen/Qwen3.5-4B.
Reader map
Know where to stop
Get Kiln running first
Follow prerequisites, install, model download, server start, /health, and /ui. If chat works, the first-run path is complete.
Train after verification
Use SFT, GRPO, and adapter workflows only after the server is healthy and you have sent one chat request.
Return when integrating
Use the API Reference and CLI Reference for tools, batch generation, adapter import/export, merge, composition, and webhooks.
Prerequisites + choose one path
Install Kiln
Desktop App · recommended
Download Kiln Desktop v0.2.15, then choose or download the Qwen3.5-4B model in the app and start the server from the GUI.
| Platform | Installer | Size |
|---|---|---|
| macOS Apple Silicon | Kiln.Desktop_0.2.15_aarch64.dmg | 8.5 MB |
| Windows | Kiln.Desktop_0.2.15_x64-setup.exe (NSIS) | 4.5 MB |
| Windows | Kiln.Desktop_0.2.15_x64_en-US.msi (MSI) | 6.8 MB |
| Linux | Kiln.Desktop_0.2.15_amd64.deb | 8.8 MB |
| Linux | Kiln.Desktop_0.2.15_amd64.AppImage | 85.7 MB |
Desktop and server release lines intentionally differ: desktop-v0.2.15 is the latest Desktop app release, and the app downloads and verifies the latest kiln-v* server binary for you.
Linux x86_64 · CUDA 12.4
KILN_VERSION=$(curl -fsSL https://api.github.com/repos/ericflo/kiln/releases/latest | sed -n 's/.*"tag_name": "kiln-v\([^"]*\)".*/\1/p')
curl -L -o kiln-linux-cuda.tar.gz \
"https://github.com/ericflo/kiln/releases/download/kiln-v${KILN_VERSION}/kiln-${KILN_VERSION}-x86_64-unknown-linux-gnu-cuda124.tar.gz"
tar -xzf kiln-linux-cuda.tar.gzLinux x86_64 · Vulkan 1.2
KILN_VERSION=$(curl -fsSL https://api.github.com/repos/ericflo/kiln/releases/latest | sed -n 's/.*"tag_name": "kiln-v\([^"]*\)".*/\1/p')
curl -L -o kiln-linux-vulkan.tar.gz \
"https://github.com/ericflo/kiln/releases/download/kiln-v${KILN_VERSION}/kiln-${KILN_VERSION}-x86_64-unknown-linux-gnu-vulkan.tar.gz"
tar -xzf kiln-linux-vulkan.tar.gzUse this on AMD/Intel Linux systems where vulkaninfo --summary lists the GPU.
macOS Apple Silicon · Metal
KILN_VERSION=$(curl -fsSL https://api.github.com/repos/ericflo/kiln/releases/latest | sed -n 's/.*"tag_name": "kiln-v\([^"]*\)".*/\1/p')
curl -L -o kiln-macos.tar.gz \
"https://github.com/ericflo/kiln/releases/download/kiln-v${KILN_VERSION}/kiln-${KILN_VERSION}-aarch64-apple-darwin-metal.tar.gz"
tar -xzf kiln-macos.tar.gzWindows x86_64 · CUDA 12.4
$KilnVersion = ((Invoke-RestMethod https://api.github.com/repos/ericflo/kiln/releases/latest).tag_name -replace '^kiln-v', '')
curl.exe -L -o kiln-windows.zip `
"https://github.com/ericflo/kiln/releases/download/kiln-v$KilnVersion/kiln-$KilnVersion-x86_64-pc-windows-msvc-cuda124.zip"
Expand-Archive .\kiln-windows.zip -DestinationPath .\kilnModel path
Download Qwen3.5-4B
Point KILN_MODEL_PATH at a local checkout of Qwen/Qwen3.5-4B.
pip install huggingface-hub
huggingface-cli download Qwen/Qwen3.5-4B --local-dir ./Qwen3.5-4B
export KILN_MODEL_PATH=./Qwen3.5-4BStart
Run the server
Server binaries bind to 127.0.0.1:8420 by default.
KILN_MODEL_PATH=./Qwen3.5-4B ./kiln serveDocker (Linux + NVIDIA Container Toolkit)
docker run --gpus all -p 8420:8420 \
-e KILN_MODEL_PATH=/models/Qwen3.5-4B \
-v "$PWD/Qwen3.5-4B:/models/Qwen3.5-4B:ro" \
ghcr.io/ericflo/kiln-server:latest serveVerify
Open the UI, check health, send chat
Open the dashboard
Visit http://127.0.0.1:8420/ui to inspect status, adapters, training jobs, and quick inference from the dashboard.
Check /health
kiln healthcurl -s http://127.0.0.1:8420/health \
| python3 -m json.toolSend chat
curl -s http://127.0.0.1:8420/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [{"role": "user", "content": "What is 2+2?"}],
"max_tokens": 64,
"temperature": 0.7
}' | python3 -m json.toolThis is the first inference checkpoint: get one response before moving on to SFT or GRPO.
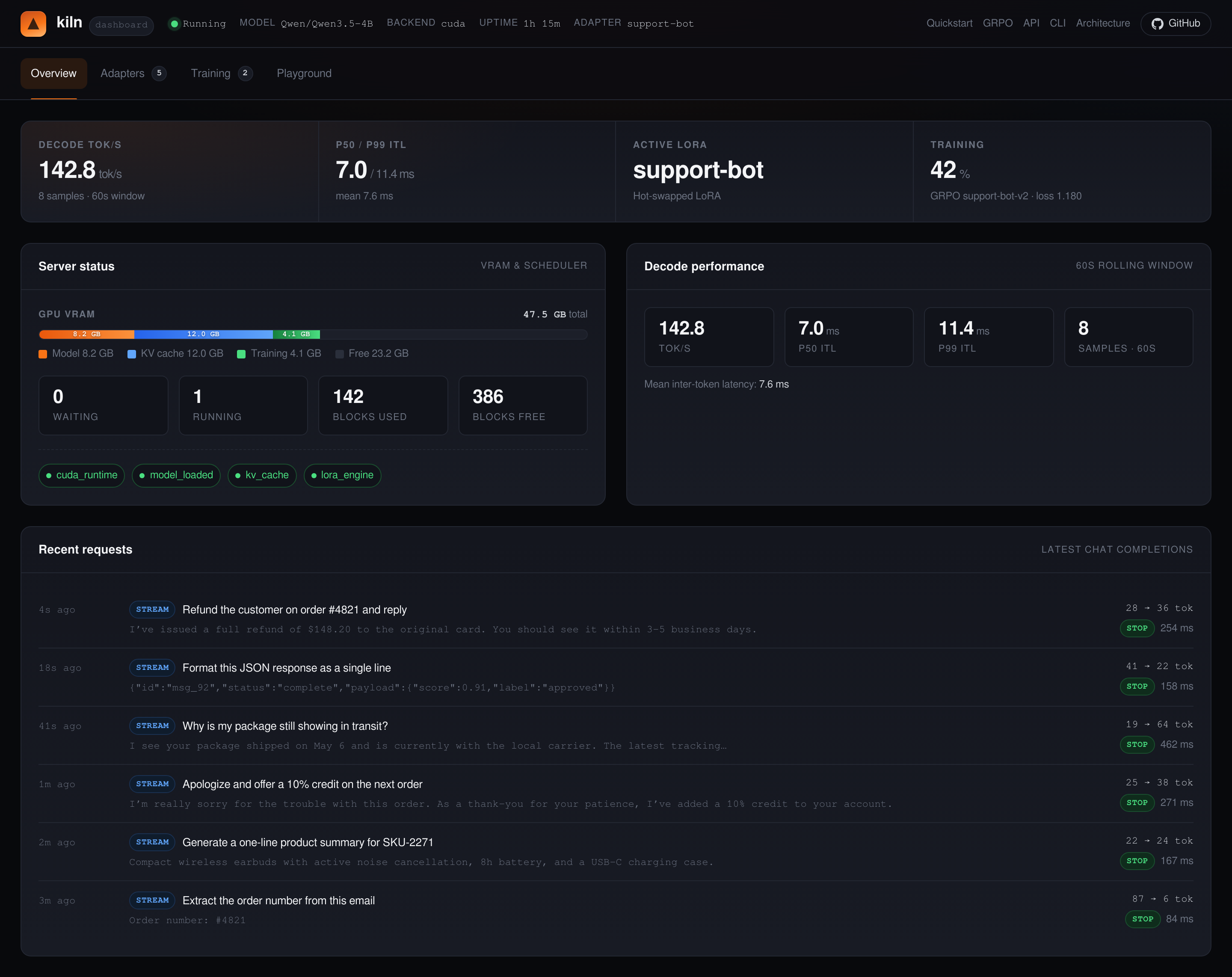
If /ui, /health, or the chat request fails, use Troubleshooting to check the model path, binary download, CUDA/Vulkan/Metal setup, Docker, and health checks before retrying.
Prefer terminal-first checks? See the CLI Reference for kiln health, training, and adapter commands.
Where to go next
Training file shapes at a glance
kiln train sft reads SFT JSONL: one chat correction per line, each with a messages array.
kiln train grpo reads a GRPO JSON request/batch: groups of candidate completions with reward scores.
See the GRPO Guide for the generate → score → train loop and the CLI Reference for full command examples.
SFT corrections
Post simple fixes to /v1/train/sft or use kiln train sft after first inference, then run kiln train status to confirm the job finished before the next chat request.
GRPO Guide
Run the generate → score → train loop against the same server.
API Reference
See inference, adapter, training, metrics, and configuration endpoints.
CLI Reference
Keep going from the terminal with health, training, and adapter commands.
Troubleshooting
Fix model paths, binary downloads, CUDA/Vulkan/Metal setup, Docker, and health checks.
Demo
Watch the first-token, hot-swap, OpenAI client, and GRPO flows.
Architecture
Understand the scheduler, block manager, GDN model path, and hot-swap design.